InArtificial Intelligence in Plain EnglishbyAbdulkader HelwanThe Basics of Fine-Tuning LLMsFinentuning LLMs on Custom DatasetApr 13Apr 13
InGenerative AIbyAbdulkader HelwanLearning a Joint Representation Space for Images and Text.Vision Language Models: Part 2Mar 22Mar 22
InArtificial Intelligence in Plain EnglishbyAbdulkader HelwanIntroduction to Vision-Language ModelsVLM: The New Era of Multimodal LLMsMar 141Mar 141
InArtificial Intelligence in Plain EnglishbyAbdulkader HelwanWhat is Grounded Multimodal Learning?An explanation articleApr 4Apr 4
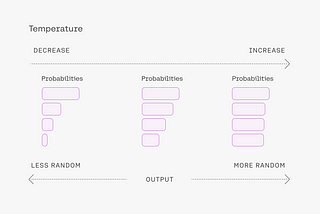
InLevel Up CodingbyAbdulkader HelwanMethods for Decoding TransformersGreedy search, beam search, and temperature scalingApr 25Apr 25
InStackademicbyAbdulkader HelwanMixFormer: A Transformer that Can SeeHow to use and Implement the MixFormerApr 3Apr 3
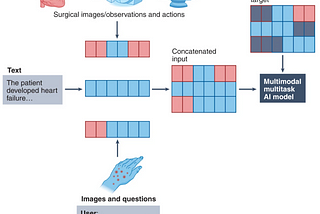
InStackademicbyAbdulkader HelwanIntroduction to Multimodal Deep LearningBasics of Multimodal ModelsApr 151Apr 151